
LLMs explained (Part 1): The 3-layer framework behind chatGPT & friends
A practical breakdown of how language models generate text, learn patterns, and improve

There are two kinds of people in AI: those who think they understand LLMs and those who have watched a Karpathy deep dive.
If you don’t know who Karpathy is, that is fine (as long as you don’t want to know about LLMs). But if you do want to truly understand what these magical models are doing, very few people can break it down like Karpathy.
Just for reference, if LLMs were a religion, Karpathy would be one of its prophets. He helped build OpenAI’s GPT models, taught at Stanford, and wrote some of the most influential papers on deep learning. Mind blowing 🤯
Now, being brilliant means nothing. I know lots of brilliant people who could only communicate with themselves (the rest of us mortals couldn’t follow what they wanted to say). However, Karpathy is a different specimen. Not just a Jedi Master of LLMs, but the Qui-Gon Jinn of AI, training the next generation of minds.
I thought I understood LLMs. Then I watched Karpathy’s video. And for the first time, it actually clicked. I saw clearly how everything fits together. This is why I wanted to write a series of 5 blog posts sharing with you all the takeaways from his 3+ hour tutorial.
My goal is to provide a written summary of it for any of you interested in digesting how LLMs work in super simple terms. Think of this as your shortcut to Karpathy’s 3-hour masterclass, distilled into a 5-part blog series.
Buckle up! This is going to change how you see LLMs.
Blog series
📌 LLMs explained (Part 1): The 3-layer framework behind chatGPT & friends (this post)
LLMs explained (Part 2): How LLMs collect and clean training data (coming soon!)
LLMs explained (Part 3): From tokens to training: how a baseline LLM learns (coming soon!)
Part 4. LLMs explained: Making LLMs actually useful through fine-tuning (coming soon!)
Part 5. LLMs explained: Reduce hallucinations by using tools (coming soon!)
Part 6. LLMs explained: Smarter AI through Reinforcement Learning (coming soon!)
LLMs are smarter than you think, but not in the way you expect
Unless you are deep into the areas of artificial intelligence, LLMs feel like magic.
You can ask them about science, history, or literature, and they will generate human-like responses (often with surprising accuracy and other with totally made up stuff). They can summarise complex research papers, analyse legal documents, write poetry in the style of Shakespeare, and a long etcetera of things.
And because they can do all these things, LLMs project a sense of “understanding”. As humans, we don’t conceive being able to talk about a topic in depth unless you know and understand it. So we tag LLMs with our own human knowledge and understanding capacities.
But, LLMs do not understand text the way humans do.
There is no reasoning, no comprehension, no awareness. What they do is simulate language, predicting the most probable next word based on vast amounts of training data. They are statistics on steroids, powered by probability and pattern recognition.
That might seem counterintuitive, but by the time you finish this series, you will see LLMs for what they truly are: remarkable, powerful, but far from the intelligent systems they sometimes appear to be.
What this blog will cover
The classical machine learning process
The 3 key stages of building an LLM
A baseline LLM model is coherent, but pretty much useless
Fine-tuning the LLM model to make it useful
The classical machine learning process
If you have worked with machine learning before, the 3 stages needed to build an LLM will feel - at least conceptually - very familiar. In fact, building an LLM follows the same fundamental process as any other machine learning model (it’s just much bigger, more expensive, and requires a ridiculous amount of data and compute power). The techniques used in each stage are way more complex, but the fundamentals are the same.
So, before diving into the 3 LLM stages, let’s first map them to something simpler: predicting house prices (wink to the Boston housing dataset). What do you need to build this predictive service?
You need to collect lots of house prices data. Aside from knowing the price of a house, you would like to know the house characteristics (bedrooms, year of construction, etc), the neighbourhood characteristics (high affluent area, public transport, etc) and maybe risk factors (flooding, etc).
You build a baseline model to capture the initial patterns in the data. For example, there a clear increase of the house price with the number of bedrooms, but only if the house is built after 1985.
You improve the existing model with more sophisticated techniques. These should help you spot all the nuances of many of the combinations in the data. For example, you run hyper-parameter tuning on an XGBoost to help it deal better with high cardinality features.
For those who haven’t worked with machine learning, whatever happens inside these 3 stages can be difficult to initially grasp. But the goal of these 3 stages is really straightforward:
(1) Get lots of data about your problem.
(2) Use the data to find patterns that help understand your problem.
(3) Throw more complicated techniques that improve upon (2) using (1).
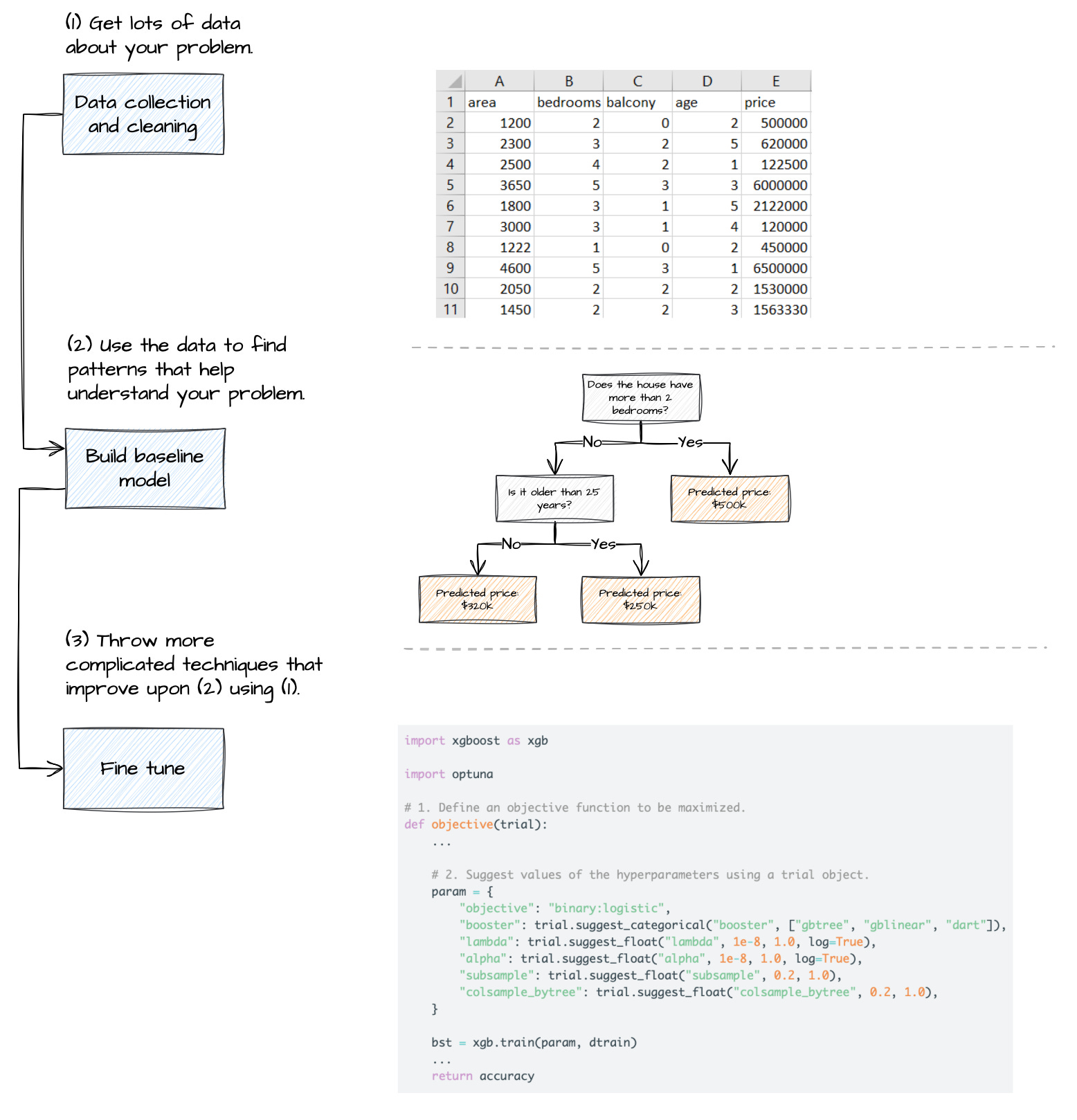
The 3 key stages of building an LLM
And do you know what happens with LLMs?
Conceptually, exactly the same. Just that instead of predicting house prices, LLMs try to predict the next best word in a given sentence. So, lets ask again the question: What do you need to build this predictive service?
You need to collect lots of text data. In this case, you basically want access to the whole of the internet or texts ever written.
You build a baseline model to capture the initial patterns in the data. In this case, a big massive neural network that it’s only goal is to predict the next word in a phrase. The goal is not be knowledgeable or truthful. The goal is to sound coherent (ie, predict the next word in a phrase correctly).
You improve the existing model with more sophisticated techniques. In this case, you then want to enhance the ability of the model to sound coherent by applying guardrails or provide it with specific examples that will make the model actually be knowledgeable and truthful.

Don’t worry if you currently don’t understand what happens under the hood in these 3 stages. That is why we have a 5 series of blogs for this.
However, let me give you a glimpse of some quirks that happen in each of these 3 stages.
What does it mean collecting lots of text data?
The first stage in any machine learning model and, of course, in building LLMs, is pulling a truck load of data. The difference between these is that, for LLMs, we are dealing with orders of magnitude we have never thought before.
LLMs need text data to work with. So, what is the single biggest source of text data we have available to us? The internet.
Now, whilst volumes of text data is definitely something that internet provides us, it is comes with a couple of problems:
How text is formatted in web pages.
It is also full of garbage.
This is why there a few specialised companies who dedicate themselves to collecting and curating all this data. For example:
And there are also open source crawlers, like CommonCrawl

You can imagine the amount of processing that needs to happen to process this vast quantity of data. We won’t go into the details here, but we can learn how HuggingFace developed their FineWeb dataset curating the CommonCrawl raw logs.


The top players in the market (the OpenAIs and co.) will of course have their own proprietary version of the collection and curation steps.
But essentially, you want to end this phase with a truck load of great quality data.
A baseline LLM model is coherent, but pretty much useless
So, now we have a truck load of great quality data. What the hell do with do with it to end up with predicting “the next word in the phrase”?
The first step is tokenization. Don’t worry, we will cover the details in a new post. Just think as tokenization as the process of changing letters (or combination of letters) into numbers. This is because numbers are what the machine understands. Check an example below.

We build a gigantic neural network. Billions of parameters. Something SUPER powerful! Hey, that is why all the top tech companies are investing billions pouring them into data centers… you need a LOT of compute power to build these gigantic predictive models. Again, don’t worry about the details right now.

I show you here the nano-gpt architecture… the GPT3 wouldn’t fit!


The nasty beast you saw above is what we then call a base model.
Remember, the ultimate goal of base models is to predict the next word accurately. There is no thinking, it is pure pattern recognition. If “Once upon a …” is super common in the text training set, then the model will give “time” a high probability of being the next word. (And of course, the bigger the model, the more accurate it will be in catching all the patterns that might exist in the text training data).
So, by definition, if it predicts the next word accurately, the model will sound coherent. But, it cannot think.
Here is an example where I copy pasted the beginning of the very famous speech from Winston Churchill addressing the House of Commons seeking to check the mood of national euphoria of having returned 300k+ troops from Dunkirk, and to make a clear appeal to the United States. As it is famous, the base model should be able to find the exact pattern of words that Churchill used. What the base model does is:
Correctly follows the sequence…
… until the sequence is too long and it deviates from the true words Churchill used. Sure, it is sounds similar, but not exactly the same.

Fine-tuning the LLM model to make it useful
Don’t get me wrong when I say that base models are not useful. It might seem I am saying the baseline LLM models are glorified autocomplete tools (and they kind of are), but its still amazing that all the internet’s knowledge is distilled within mathematical parameters. But, unless you want to recite like a parrot, they won’t help too much.
This is why, fine-tuning exist. Fine-tuning is the process where, we take the gigantic beast of the baseline model, and show it examples that resemble conversations between humans. Take the screenshot from Karpathy’s video as an example.

This is how we want the LLM to behave. Provide answers and being nice and helpful. Let’s try the question with a baseline model (Llama3 8B-text) and with a fine-tuned model (DeepSeek r1: 14b)


We will cover how fine-tuning to get to this stage works in future posts. For the moment, I wanted to show you how important the fine-tuning step is for LLMs. Without it, we would be left with a glorified autocomplete tool which can’t really help us answer our questions.
Key takeaways from part 1: How LLMs are built
LLMs are not intelligent, just statistical beasts. They don’t “understand” text like humans do. Instead, they predict the next most likely word based on vast amounts of training data. Think statistics on steroids.
Building an LLM follows the same 3-step logic as any ML model:
1️⃣ Collect massive amounts of data (ideally, the entire internet).
2️⃣ Train a baseline model to capture patterns (but at this stage, it's just a glorified autocomplete).
3️⃣ Improve the model with fine-tuning and guardrails to make it useful.Baseline models sound coherent but are mostly useless. Predicting the next word makes them sound real, but they have no reasoning, truthfulness, or intent. It’s “just” pattern matching.
Fine-tuning turns a random word predictor into an actual tool. This is where things like knowledge, factual consistency, and human alignment come in.
In the next blog (Part 2), we will dive into how data is collected and prepared for training a baseline LLM model.
Now, I want to hear from you!
📢 Before reading this, how did you think LLMs worked?
Did this post change your perspective on what’s actually happening under the hood?
What is one thing about LLMs that still feels like magic to you? Or, on the flip side, what is one thing that now seems way less impressive after understanding the mechanics?
If you have built or worked with machine learning models before, how does the LLM training process compare to your experience?
Drop your thoughts in the comments! I’d love to hear your takeaways, questions, or even your favourite LLM misconceptions. Let’s make this a conversation.👇
See you in the next post! 👋
Further reading
If you are interested in more content, here is an article capturing all my written blogs!

I’ve been exploring ways to reduce hallucinations in large language models and improve their reasoning capabilities. Inspired by recent discussions on LLMs, I developed a concept called ATLAS (Adaptive Thinking and Learning through Alternative Solutions), which is based on the ACDQ framework:
- Act: Direct the model to behave like an expert in any field.
- Context: Provide detailed, rich information to improve understanding.
- Deep-thinking: Encourage the model to reason deeply before responding.
- Questions: Prompt the AI to ask clarifying questions to enhance collaboration and accuracy.
By combining this with multi-path training strategies that expose the model to diverse problem-solving approaches, ATLAS aims to improve robustness, reduce contextual uncertainty, and significantly reduce hallucinations through enhanced contextual understanding and self-verification.
This approach could advance transformer-based models by integrating comprehensive context, deep reasoning, and diverse solution strategies.
Would love to hear your thoughts or feedback!