
LLMs explained (Part 2): How LLMs collect and clean training data
You can't train a great AI on junk data. So how do companies collect, clean, and process the trillions of words that fuel modern LLMs?

This week, I want to dive into our first real technical deep dive into LLMs. But don’t worry, I won’t be throwing math formulas or complex algorithms at you. 😉
In Part 1, we covered the 3 key stages of building an LLM:
Collecting massive amounts of data
Training a base model
Fine-tuning it to be useful
Today, in Part 2, we are zooming in on the first (and often overlooked) stage: data collection and cleaning.
I know plenty of data scientists who get all hyped up about training models but cringe when it’s time to clean data. But like it or not, the old rule "Garbage in, Garbage out" applies just as much to LLMs as it does to classical machine learning.
That is exactly why I want to cover what happens before we even start training the first baseline model, because, in many ways, this step is just as important as the model itself.
⚡ Reminder: This series is inspired by Andrej Karpathy’s deep dive on LLMs. If you haven’t watched it yet, you definitely should!
Blog series
✅ Part 1. LLMs explained: The 3-layer framework behind chatGPT & friends.
📌 Part 2. LLMs explained: How LLMs collect and clean training data (this post!)
Part 3. LLMs explained: From tokens to training – how a baseline LLM learns (coming soon!)
Part 4. LLMs explained: Making LLMs actually useful through fine-tuning (coming soon!)
Part 5. LLMs explained: Reduce hallucinations by using tools (coming soon!)
Part 6. LLMs explained: Smarter AI through Reinforcement Learning (coming soon!)
The secret behind LLMs is the data
If you have played around with ChatGPT, Claude, or any modern LLM, you have probably had moments where their responses feel almost too good. But, in other instances, it seems like it just makes things up.
In post 1, we briefly covered that LLMs don’t really think; they predict. Every response they generate is based on one thing: statistical pattern matching from massive amounts of text data.
Think for a moment about the following scenario.
Would ChatGPT be anywhere near as capable if it had been trained on just a few hundred textbooks? Or what if it had access to all written text ever generated, but, only on philosophy?
If the answer is no, then I agree with you.
In both cases, the model would either have too little data or a narrow, biased view of the world. LLMs don’t “just” need data: they need vast, diverse, and well-structured data to be effective.
This is why data collection and curation are as important (if not more) than the actual model itself.
What this blog will cover
The scale of data LLMs need to work. Trillions of words. With a “T”.
Where this data comes from. Common Crawl, Wikipedia, Books, Code, and more.
How do companies clean and prepare data for LLMs. The internet is full of crap.
Let’s dive in!
The scale of data LLMs need to work.
When you hear that modern LLMs have billions of parameters and train on trillions of tokens, it sounds overwhelming. But what does that actually mean in terms of raw data?
How many words are needed to build trillion token models?
Before we answer that, let’s clarify two fundamental concepts: parameters and tokens. Understanding these will help explain the sheer volume of data required to build modern LLMs.
Parameters: The internal "knobs" and "switches" the model adjusts to learn from data. Each parameter represents a weight in the neural network that helps the model predict the next word/token based on past training.
💡 Analogy: Think of parameters like the number of connections in a brain (more parameters mean a larger capacity to learn complex patterns).
Training Tokens: Tokens are how we transform human readable format into a numerical format that a machine can understand. 1 token might not be 1 word; it can be part of a word, or even punctuation.
💡 Analogy: Training tokens are like the number of books a person has read (the more they have read, the broader their knowledge).
Now that we have a clearer understanding of parameters vs. tokens, let's look at real-world numbers. How much text does it take to build trillion-token models? Here is a quick breakdown based on publicly available data:
Let me spell out the 11 trillion with numbers.
11 trillion = 11,000,000,000,000. 12 zeroes. To put that into perspective, if words were money, 11 trillion words is the equivalent of purchasing Apple, Microsoft, and NVIDIA (combined).
These 11 trillion words aren't just repeated text. For example, the word "the" may appear millions of times, but LLMs don’t store each instance separately—it’s encoded as a single token. (Fun fact: In GPT-4o, TikTokenizer assigns "the" the token ID 3086.)
So, where do you even find trillions of words to train a model? The answer, unsurprisingly, is the internet. But, you might be surprised to know that there are more sources aside from the internet.
Where this data comes from
It is estimated that there is 180+ zettabytes of data in the internet (for reference, one zettabyte is equal to 1 trillion gigabytes). If we are conservative and say that 10% of this is text data, then we are left with a tiny amount (irony mode on) of 18 zettabytes of data. So, we can’t say that volumes to train a model would be an issue…
But, there is a problem with the internet. And if Melisandre had lived in our age, she would have said:

And she'd be right.
There are 2 main problems that the internet comes with when trying to collect its data:
How a webpage is formatted. Unfortunately, it is not as easy as scraping “clean text”, scrapers also ingest raw HTML, ads, sidebars, and all kinds of junk.
The quality of the data you can find in the internet. Spam, misinformation, and low-quality content need to be filtered out.
Problem 1. How a webpage is formatted.
Here is a screenshot of how this current blog is formatted. It’s full of HTML code, and each webpage is formatted differently.
So, unfortunately, the internet does not comes with a “Download PDF” button. There is a lot of cleaning to do to “just” extract the human readable text content.
Problem 2. The quality of the data you can find in the internet.
Wouldn’t it be a fun experiment to build an LLM just based on Reddit’s data? Fun for sure… but useful? Pretty questionable.
This question clearly highlights that there are more respectable sources than others (at least if you want to build something factual). We can get a glimpse of what OpenAI believes is valuable data from their GPT3 paper “Language Models are Few-Shot Learners”.
Here they provide some details on what type of data they use:
Before filtering: 45TB of compressed plaintext (~90TB uncompressed).
After filtering: The dataset was reduced to 570GB
In addition, OpenAI explain in their GPT3 paper, the different types of sources they use and how important they are in GPT3. (PS, the total here is 490GB, so probably other sources played a role too to make up to the total of 570GB)

From the table above, we can see that:
The biggest amount of data was CommonCrawl with 400GB of data.
However, the learning process spent more time learning (epochs column) on Wikipedia, WebText2 and Books1.
These are high quality sources of data, which the model values much more than the brute force of CommonCrawl. Specifically:
Wikipedia: English-language Wikipedia, at 10 GB, offers broad factual knowledge.
Social Media and News: WebText, derived from Reddit-linked pages with high karma, ensures quality, and news articles add current events.
Books1 and Books2: Datasets like Books1 and Books2, used in GPT-3, provide literary content. Although it must be said that OpenAI seem to have dropped these due to copyright infringements (yeah, there is a lot of that going on).
CommonCrawl: A non-profit providing the largest open dataset, captures vast web content
Given that CommonCrawl is the biggest source of data, although probably the most complicated one to clean and prepare for training LLMs, lets focus on how are companies curating this open source dataset.
How do companies clean and prepare data for LLMs
What is CommonCrawl, and why does it matter?
CommonCrawl an open nonprofit initiative, has been archiving the web since 2008, storing vast amounts of webpage content, metadata, and site structures. Every month, its crawlers scan millions of websites, capturing everything from news articles and blogs to scientific papers and Wikipedia entries. Today, CommonCrawl's dataset spans petabytes of data, making it one of the largest free text repositories in the world.

What are the pros & cons of CommonCrawl?
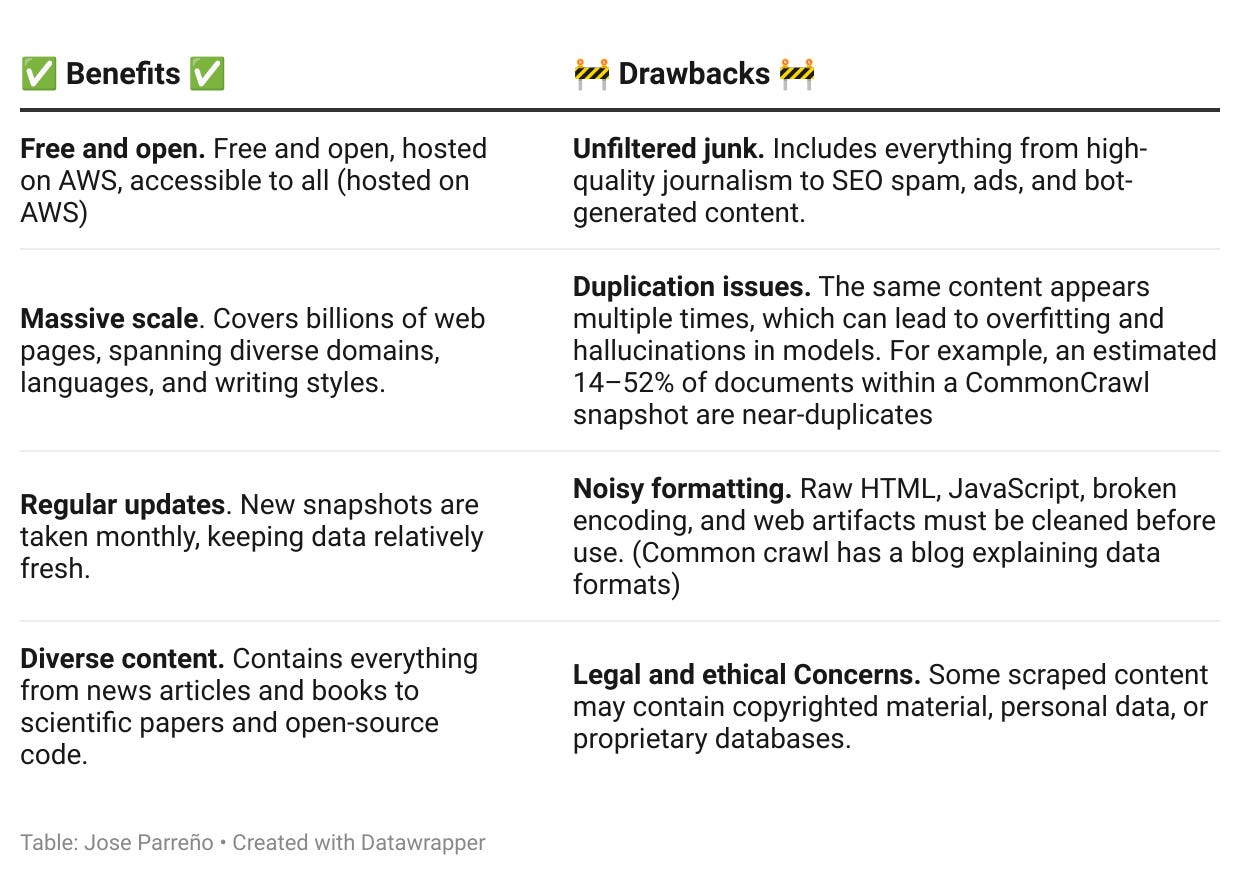
Why AI companies use CommonCrawl (despite its flaws)
Even with its messy, unfiltered nature, CommonCrawl remains a core component of LLM training because no other dataset offers its scale and diversity for free. Instead of avoiding it, companies like OpenAI, Anthropic, and Meta have developed sophisticated filtering pipelines to clean, deduplicate, and enhance CommonCrawl data before feeding it into their models.
For AI companies, CommonCrawl is a starting point, not the final product. In fact, we know that OpenAI and Anthropic have their own scrapers, but we don’t have visibility into how they clean their data. In the next section, we will look into how this messy CommonCrawl data can be cleaned thanks to the FineWeb project.
The FineWeb project: A publicly available alternative to OpenAI’s internal processes
OpenAI, Anthropic, and other AI labs use proprietary methods to refine web-scale datasets, ensuring models learn from high-quality, diverse, and reliable sources while filtering out spam, duplicates, and harmful content.
For researchers and the broader AI community, understanding how this filtering process works is difficult (probably most of it happens behind NDA walls).
This is where FineWeb comes in.
FineWeb is an open-source initiative designed to replicate the high-quality dataset curation process used by companies like OpenAI. Instead of keeping filtering methods secret, FineWeb documents every step of the process, allowing researchers to see how large-scale web data is cleaned, deduplicated, and enhanced before training an LLM.
Some FineWeb stats
15-trillion tokens
44TB disk space
Derived from 96 CommonCrawl snapshots
Models trained on FineWeb have demonstrated superior performance compared to those trained on other datasets like C4, Dolma-v1.6, The Pile, SlimPajama, and RedPajama2.
Why does the FineWeb project matter?
Basically, it’s one of the best windows into how companies like OpenAI might prepare data at scale.
It reveals best practices for filtering out low-quality content, duplicates, and biases in web-scale datasets.
It offers a reproducible framework, meaning others can experiment, tweak, and improve on existing filtering methods.
It bridges the knowledge gap, making high-quality dataset curation accessible to those outside major AI labs.
So, the millon-dollar question (or lot’s of millions): how does FineWeb clean CommonCrawl data?
The 8 steps FineWeb uses to clean data


Key takeaways from part 2
Garbage in, garbage out applies to LLMs. The quality of the model depends on the quality of its training data.
LLMs need trillions of tokens to be useful, requiring data sources like Common Crawl, Wikipedia, and books.
Not all internet text is valuable. Companies filter out spam, duplicated content, and misleading information before training.
Pre-training isn't enough. After collecting and cleaning data, companies refine it with careful filtering and deduplication before even starting model training.
Now, I want to hear from you!
📢 Training data is the foundation of LLMs, but not all sources are equally useful.
What are your thoughts on how LLMs handle data collection?
Should companies be more transparent about their datasets?
Or do you think filtering too much could limit model performance?
Drop your thoughts in the comments! Let’s make this a conversation.👇
See you in the next post! 👋
Further reading
If you are interested in more content, here is an article capturing all my written blogs!

Underfitting can limit model's performance, and companies NEED to be more transparent and SIMPLIFY what they do with data collected from people.