
LLMs explained (Part 3): From tokens to training – how a baseline LLM learns
How raw text becomes numbers, why tokenization matters, and what an LLM actually learns when it starts from scratch.

This week, I want to break down a crucial but often overlooked step in building LLMs: how raw text becomes structured data, and how a baseline model learns from it.
In Part 1, we covered the 3 key stages of building an LLM. In Part 2, we zoomed in on the data collection and cleaning process. Today, in Part 3, we focus on tokenization—the step where text is transformed into numbers—and what happens when we train a baseline LLM for the first time.
How does an LLM go from knowing nothing to generating text? What exactly is it learning? And why do even the largest models start as nothing more than predict-the-next-token machines?
Let’s dive in!
⚡ Reminder: This series is inspired by Andrej Karpathy’s deep dive on LLMs. If you haven’t watched it yet, you definitely should!
Blog series
✅ Part 1. LLMs explained: The 3-layer framework behind chatGPT & friends.
✅ Part 2. LLMs explained: How LLMs collect and clean training data
📌 Part 3. LLMs explained: From tokens to training – how a baseline LLM learns (this post!)
Part 4. LLMs explained: Making LLMs actually useful through fine-tuning (coming soon!)
Part 5. LLMs explained: Reduce hallucinations by using tools (coming soon!)
Part 6. LLMs explained: Smarter AI through Reinforcement Learning (coming soon!)
LLMs don’t see words, they see numbers.
When you type a sentence into ChatGPT, you see words. The model, however, sees nothing but numbers.
Before an LLM can generate text, it needs to break every sentence into tiny pieces. These pieces are what we call tokens. Did you know that "running" and "runner" might be broken down differently depending on the model? Or that GPT-4's tokenizer doesn’t treat “New York” as a single unit, but some models do?
Tokenization is the hidden first step in how LLMs process text. But even after text is tokenized, a baseline LLM starts off knowing nothing. It doesn’t understand language, facts, or context. Instead, it learns one thing: how to predict the next token. And from this simple task, intelligence-like behaviour emerges.
Today, we dive into what happens when raw text meets neural networks—and how this foundational step shapes everything LLMs can and can’t do.
What this blog will cover
A reminder of why cleaning data is important. Scraping the internet is messy.
Tokenization. How text becomes data.
What is a baseline LLM model trained for? And how does it learn?
LLMs are encoding-decoding machines. Words → Tokens → Parameters → Token → Word.
The costs which make baseline LLM model training only accessible to a few. The reason why nvidia stock exploded.
Let’s dive in!
A reminder of why cleaning data is important.
Before getting into Tokenization, let’s briefly review what we covered in Part 2. LLMs explained: How LLMs collect and clean training data. In the previous blog we learnt how the FineWeb project explained the cleaning process of CommonCrawl, a massive open-source dataset that has been scraping the internet since 2007. This cleaning process is required so that LLMs are fed with a high quality and structured dataset. As a reminder, you see 2 screenshots below, representing the FineWeb cleaning process and a side by side example of messy vs clean data.


💡 Fun fact: Even after cleaning, huge portions of the internet are discarded. For example, OpenAI, in their GPT3 paper “Language Models are Few-Shot Learners”, mention that they begin with 90TB of uncompressed text, but after cleaning and filtering, are left with 570GB.
Tokenization. How text becomes data.
So, we now have cleaned text, free from unnecessary clutter. But there is 1 huge problem: machines don’t "see" text like we do.
When we read a sentence like "Albert Einstein was a German-born theoretical physicist who developed the theory of relativity", we understand the meaning. We recognise Albert Einstein as a person, "German-born" as a nationality, and "theory of relativity" as a scientific concept.
But, to a computer, this is just a sequence of characters: “A l b e r t …” This format is useless for machine learning because computers don’t process words or sentences.
Machines need numbers. And this is where tokenization comes into play.
What is tokenization
Tokenization, in the context of Large Language Models (LLMs) and language text processing, is the process of breaking down text into smaller, manageable units called tokens. These tokens can be words, subwords, characters, or combinations of words and punctuation.
The primary purpose of tokenization is to convert text into a numerical format where each unique token is assigned a specific numerical index or ID, allowing the model to analyse relationships based on these token sequences.
Now, all this sounds a bit too theoretical. The best way to understand tokenization is to see it in action. Below, you will see a screenshots from TikTokenizer, where we cover different scenarios:

Then, how are tokens built?
The example displayed above is just 1 way how text can be broken down into tokens. Different tokenization methods exist because languages are complex. Some models need to handle rare words better, while others prioritise efficiency. Let's look at how different companies approach this challenge:
Byte-Pair encoding (BPE). OpenAI's GPT series, including GPT-3 and GPT-4, utilise Byte-Pair encoding (BPE) for tokenisation. This method iteratively merges the most frequent pairs of characters or character sequences in the text, effectively balancing the representation of common and rare words. BPE is particularly useful for OpenAI’s GPT models because it balances efficiency and flexibility, making it well-suited for large-scale generative tasks.
WordPiece tokenization. Wordpiece tokenization is similar to BPE but focuses on saving the final vocabulary rather than the merge rules. It tokenizes words by finding the longest subword that is in the vocabulary. Google’s WordPiece is optimised for models like BERT, which require a strong vocabulary structure for tasks like sentence classification and named entity recognition.
Character-based tokenization. Commonly used in models for languages like Chinese, where each character can represent a concept or idea.
So, what does it mean that GPT4 has 13 trillion tokens?
Well, exactly what it sounds: that, from all the text sources OpenAI has decided to use, they are distilled using the BPE encoding into 13 trillion unique tokens.
Token count affects how a model generalises language. More tokens mean:
A larger training dataset, helping the model recognise more patterns.
Better handling of rare words, phrases, and specialised knowledge.
More diverse linguistic structures, making responses more natural and context-aware.
However, more tokens don’t necessarily mean better performance. The quality of tokens and how they are used in training matters just as much as the raw number.
For example, you can find a specific sequence of tokens in an Instagram post or you can find the same sequence in the Wikipedia. It is up to the team building the LLM to decide how much weight does it give to the sources of the data. As we saw in Part 2. LLMs explained: How LLMs collect and clean training data, GPT3 trusted the sequences coming from Wikipedia more than the ones coming from the rest of the Internet.

Now that we have turned cleaned text into tokens, the next step is training the model. But what exactly is a baseline LLM trained to do—and how does it start learning from scratch?
What is a baseline LLM model trained for? (and how does it learn)
✅ Primary goal
The goal of a baseline LLM model is to predict the next word on any sequence correctly. If you think about it, the golden star metric is to become the most perfected autocomplete tool in history.
❌ Not a goal
Of course, if you do reach this level of glorified autocompletion, then by definition, the LLM will sound totally human. But sounding human does not make the LLM be factual.
🧐 Examples
Below you can see an examples of how a powerful baseline LLM (Llama 3.1-70B-Base) responds. It’s not the most powerful of baseline models, but it was the only one I could fit in my laptop 😅.

→ Did it answer the question? Nope.
→ Does it sound more factual than most of my friends? Yep.
How does the baseline model learn how to predict the next word in a sequence?
Framing an example
Let’s understand this first through a simple example. Imagine that:
Your input data consists of 9 words (or 9 tokens).
[“The”, “Eiffel”, “tower”, “is”, “in”, “France”, “London”, “New”, “York”]You are only interested in the model learning how to complete the sentence:
"The Eiffel Tower is in __"For this experiment, the model can only choose from 3 possible words.
Check the setup through the following diagram.

The first iteration
1 way in which predictive models make choices is through probabilities. As this is the first iteration, the model might simply give each of the 3 choices an equal chance of being selected. In the example, below this is represented with “France”, “London” and “New” having a 33.33% chance of being chosen.
On its first guess, the model randomly selects 'France.' The model then checks the correct answer and says “Hey! I got it right! This means that I should upweight my {France} knob upwards”.
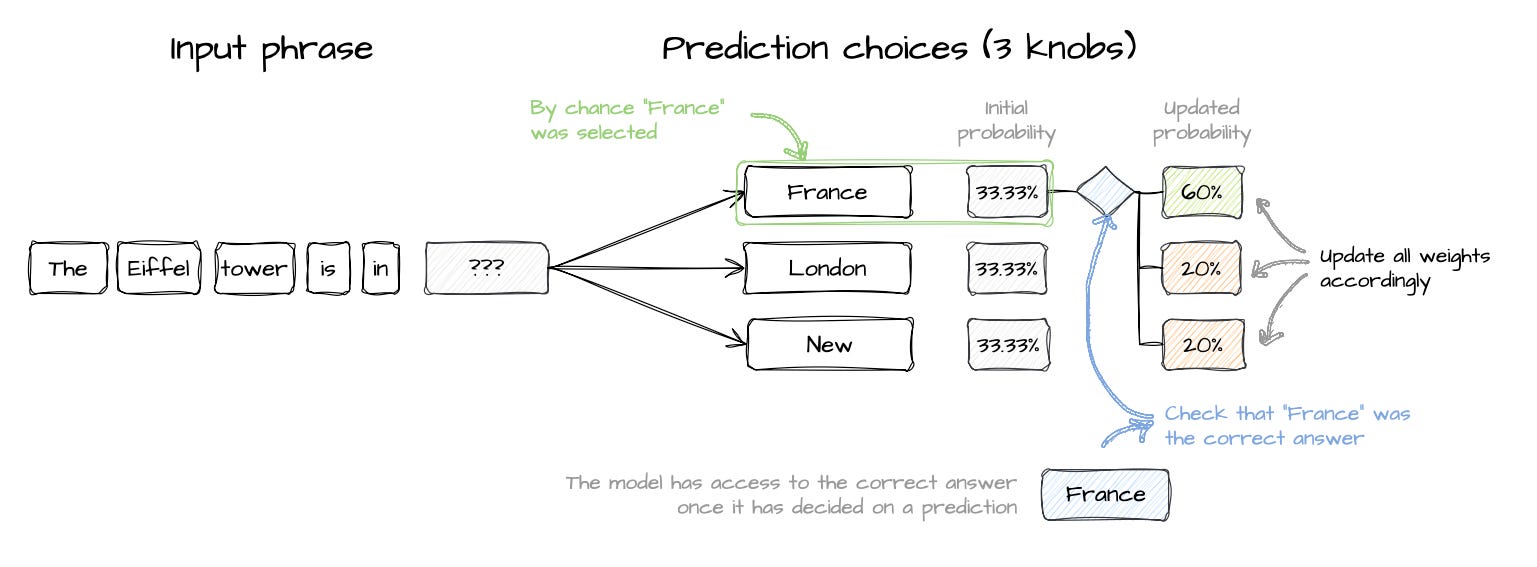
It got lucky! But luck isn’t learning, let’s see what happens next.
The second iteration
Now, we tell the model to make another pass with the same input phrase. In this case, because it learnt that “France” was better in the previous trial (ie, it has a higher probability than the other 2 options), then it chooses it again. And, because it once more got it right, then the “France” knob dials up again.
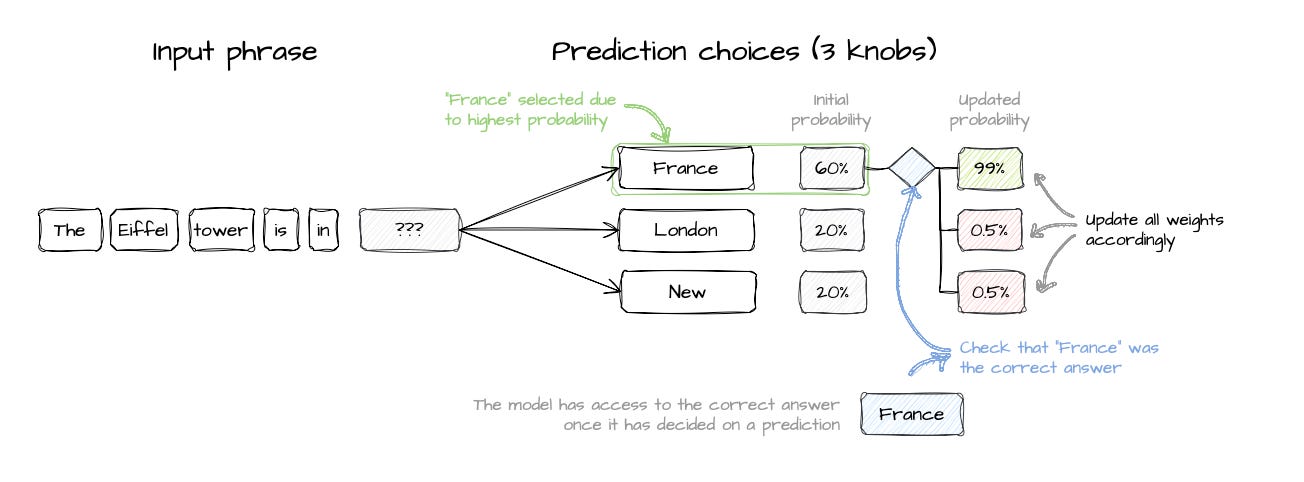
The stopping moment
In the 2nd round, “France” got to a 99% probability. Should we do a third round and get to 99.999%? The answer to that is actually not a simple “Yes” or “No” answer. In machine learning and in LLMs there is a concept called “error rate”, where we compute the average amount of errors we get when testing our “knob” parameters on data.
In this case, if we were to run 1,000 times the input phrase “The Eiffel tower is in __” with the “France” knob set at 99% probability of being chose, then we would probably get an error rate of 1%. If we are comfortable with a 1% error rate, we can stop training the baseline model here.
A more real-world example taken from Karpathy’s video.
In his tutorial, around 38”, Karpathy show cases a simple LLM he is building. Below you can see 2 screenshots:
The first shows how, with 20 iterations, the output of the LLM is pure gibberish. It makes no sense at all. It clearly has the knob probabilities similar to what we had in our 1st iteration (probably with equal chances of any word being chosen).
The second screenshot shows how, after 400 learning passes, it begins to be more coherent. Of course it is not GPT4 coherence level, but it show cases what the baseline model is trying to do.


Where does the baseline LLM work?
It regurgitates things from memory pretty well. For example, I copy pasted an extract from the Wikipedia and fed it to the LLM. I was expecting it to follow the sequence very similarly with what I read in Wikipedia, and it more or less did. Like, what are the chances that, passing 2 big paragraphs, the returning next words from the LLM would have been something on the lines of the UNESCO World Heritage Site? Well, that is exactly what the LLM returned.


Where does the baseline LLM fail?
Pretty much in every other instance. It’s great at writing coherent sentences, but it just diverges. The screenshots below (taken from Karpathy video) show how, for the same input, the baseline LLM just hallucinates wildly.



Now that we have understood that words become tokens, and tokens are passed through parameters (“knobs”) to predict the next item in a sequence, let’s put it all together in a visual diagram.
LLMs are encoding-decoding machines.
If you’ve made it this far—thank you! 🙇 Now, let’s pull everything together and revisit how a baseline LLM is built step by step.
First, we need words. So clean and collect.
Words are useless to machines. So we need to tokenise them into numbers.
The learning happens when we pass sequences and try to predict the next token in the sequence. These are done through tweaking parameters (“knobs”).
The prediction is taken from the token with the highest probability.
Finally, the token is mapped back to its corresponding word / words / punctuation for a human to be able to interpret.
These stages describe an encoder - decoder machine:
We encode words to numbers.
Something happens in between
We decode numbers to words.
From the table we presented in Part 2. LLMs explained: How LLMs collect and clean training data, we saw that GPT4 is estimated to have used 13 trillion tokens and 1.8 trillion parameters.

Graphically this would be something like the following.

Hopefully, this final diagram brings the mental puzzle together in a much more cohesive way!
The costs which make baseline LLM model training only accessible to a few.
A final section I wanted to cover is why isn’t the whole world building these baseline LLM models? Conceptually, they aren’t too different from what existed in the past.
The reason is purely related to brute force and money. Unlike traditional ML, training neural networks with billions or trillions of parameters isn’t something that can be done by renting some AWS compute resource. You need some seriously big pockets and access to beefed up hardware to make this happen. Needless to say that these companies also hire the top talent in the world, so salaries are also not cheap.
My favourite article on AI training costs comes from Epoch AI. I reference below the 2 charts I love the most.

You see the y-axis representing cloud computing costs? Well, most of the companies building these models are using NVIDIA hardware… guess what happened with NVIDIA’s stock in the past few years 🚀🚀🚀🚀

So, unfortunately, until the technology gets a bit more democratised, we are all in the hands on probably less than 20 companies in the whole world (honestly, nothing new, the internet in owned by Google because who uses Bing or Yahoo?).
Key takeaways from part 3
Tokenization is how raw text becomes data. LLMs don’t read words; they process tokens—subword units that make text computationally manageable.
Different tokenization methods exist for different needs. Byte-Pair Encoding (BPE), WordPiece, and character-based tokenization serve different trade-offs in efficiency and language structure.
A baseline LLM model is just a probability machine. It learns to predict the next token based on statistical patterns in training data, not meaning or reasoning.
Training costs are astronomical. The sheer compute and infrastructure required to train an LLM makes it accessible to only a few major players, which is why NVIDIA stock skyrocketed.
Now, I want to hear from you!
📢 Tokenization shapes how LLMs process text—but it’s just the first step.
What do you think has a bigger impact on model performance: tokenization methods or the number of parameters in the neural network?
Should models prioritize smarter tokenization to reduce complexity, or is sheer scale (trillions of parameters) the only way forward?
Drop your thoughts in the comments! Let’s make this a conversation.👇
See you in the next post! 👋
Further reading
If you are interested in more content, here is an article capturing all my written blogs!

Nltk.tokenize and word2vector.tozen had a huge difference in results. But on the other hand we can turn off parameters that are not in use... Deepseek maybe...